What is Open Data and how can Commercial Insurers take the most out of it?
Published on 15 de February de 2021


Open data refers to any kind of information that can be accessible and found on the Internet. Corporates from all industries are using this type of data in order to know their customers more and better.
Managing open data allows corporates to increase data quality, monitor events and changes, and automate processes. The type, size, source, and applicability of the data can be of infinite variety.
Any source that contains data related to business customers and their risks.
The most common business data sources available include information about their financial statements, property data, criminality levels, catastrophic risks, news, opinions from clients, information from the managers, number of locations, etc. While some of these sources are useful to update our current data, other sources can be useful to automate processes and increase the risk assessment accuracy.

1. To improve current processes
Data quality is the first aspect we have to improve. We need to know what is the reality of our customers or potential customers in order to improve the results of our daily tasks. This is also a must before adding any complexity to our processes.
This problem is common: based on our projects, an average of 45% of insurer’s commercial customers have inaccuracies in their business activities or/and their addresses.
Problem:

We are an example of this. In the image above, we can see the data we sent to the insurer when we bought a business insurance policy right after establishing our company. However, like any other business, many things have changed in only two years. The insurer has been renewing our policy without updating our data, and yet this information can be found on open data sources.
Solution:
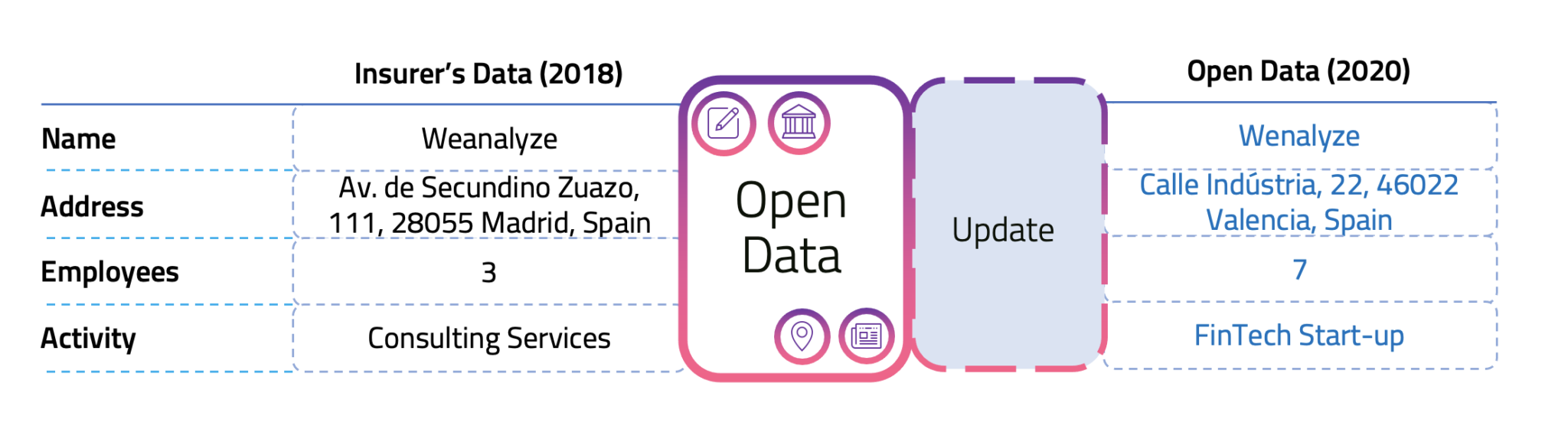
Implementing open data sources can help to update inaccuracies and outdated data in an automated way. We must know what is the reality of our customers in order to make good decisions.
1. To automate processes
Once the data we manage is adjusted to reality, process automation becomes feasible. By establishing a connection with our systems and open data sources, process automation can be applied to underwriting and renewals to reduce times and increase. A before and after example of an underwriting process for business property insurance can be seen below:
This is a major concern as insurers base risks and premiums are on the data they receive. The information we can find online about a business is either shared by themselves, their clients, or public institutions/business databases. The quality has to be assessed differently depending on the source and type of data.
Businesses share information on their website, social media profiles, and on their Google Business Card. One of the ways we can confirm if the data quality is good is by checking when it was published and if it matches between the different data sources. For example, if the business address we find on Google Maps, the business website, and their social media profiles are the same, then we can be assured this data point is correct and updated.
When the data is found on public registers or opinions, it often comes with the date on which the information was published, allowing us to understand if the insurer’s data is more recent or not.

We know that the Internet is full of trolls and an angry customer can be the worst nightmare for a business. This may be the part that causes more doubts to insurers, but there is a way around it that we can see in the example below:
We can see on the image above that Business 1 has a higher rating than Business 2. However, it only received 7 opinions and all of them were published in only one day. Therefore, the number of opinions and dates have to be considered when giving importance to this information.
In this case, opinions will not be considered for Business 1, which means it is either a young business or clients do not like to share opinions about it. The result we will get in this comparison is that Business 2 is strong, popular, and has a good rating.
It depends on the type of risk. I believe SME underwriting and renewals processes will become fully automated in the future as having manual tasks involved is not efficient nor profitable for such small premiums. There is a competition going on in the SME space: the insurer that manages to cut costs on these processes will be able to offer very competitive prices to their SME customers.
For bigger risks, it is a bit more complex. The size of these premiums enables the insurer to invest in HR without seeing a substantial increase in the premium. Also, an automated system is likely to commit mistakes that we can not allow in certain types of risks. The key here is to apply Machine Learning techniques and train the system to reduce errors while having human supervision. This human supervision is not only useful to prevent these mistakes but to find new ways to apply open data.
So, what should a commercial insurer start with?
In sum, the first and mandatory task we have to do in this data world is to improve what we currently have by increasing data quality. Once this is done, we can then consider adding complexity to our processes and start the path of building a more automated and efficient insurance company.
If you have any question, please feel free to leave a comment below or reach me out at roger@wenalyze.com


